
Trước khi đi vào phần chính, xin phép chia sẻ quá trình triển khai từ đầu con zabbix này. Hiện con cũ đang xài 5.0, được upgrade nhiều lần từ bản 3.2 lên. Tuy nhiên do nhiều vấn đề xảy ra nên team quyết lên 5.4 thì đập đi xây lại, cuối cùng dừng chân với postgresql
Việc thay đổi database backend cũng chỉ là thử nghiệm chút thôi, trước đây cũng chưa từng dùng postgres hồi nào. Nhưng quá khứ đã từng sử dụng:
+ Mysql inodb: đúng theo sách giáo khoa, tối ưu các thứ như tách mỗi bảng thành 1 file, mọi thứ vẫn ổn cho tới khi dữ liệu lên tầm 100GB thì bắt đầu có những case lỗi xảy ra, đôi khi mysql hoạt động full CPU, dù đã tối ưu rất nhiều nhưng slow query vẫn thường xuất hiện. Mysql thì vốn đã phân mảnh, do có 2 nhánh phát triển do oracle cầm đầu và nhánh mariadb cầm đầu, vì thế các con số để tunning tương ứng mất rất nhiều công sức tìm hiểu của anh em, mà tốn công với DB thế thì AE bỏ nghề làm DBA lương cao hơn devops vs SA nhiều 😀 Trong team bắt đầu manh nha ý nghĩ đổi sang database backend khác.
+ Oracle database: team có 2 ông DBA oracle nên nghĩ rằng đổi sang orac thì sẽ ngon hơn. Tuy nhiên khi triển khai đã gặp các vấn đề:
– Zabbix không có bản build sẵn chạy với oracle: OK cái này k sao, down source về rồi tự build là xong, cái này dễ.
– Các table có dung lượng lớn của zabbix: history*, trend* tầm 7 bảng chứa dữ liệu chính và rất nặng. Với mysql bên mình thấy zabbix select where clock xxx nên trường clock của mỗi bảng được đánh partition theo ngày, cứ mỗi ngày bên mình đánh thành 1 partition khác nhau ==> import data từ source zabbix vào sau đó drop hết các bảng mặc định đi rồi sửa lại là xong. cái này vẫn dễ.
– Ban đầu thiết kế DB zabbix sẽ nằm chung phần cứng với cụm database RAC 5 node hiện có, tuy nhiên phát hiện ra ông zabbix xài charset khác với mặc định của đám oracle, cái này thường các ông DBA, hay dev cũng chả sửa
Incorrect parameter "NLS_NCHAR_CHARACTERSET" value: "AL16UTF16" instead "AL32UTF8, UTF8".
Vậy là dựng riêg con oracle khác. Sau 1 tuần vận hành, add thêm 50 con máy vào thì thường xuyên queue > 10m. không có slow query tuy nhiên thỉnh thoảng zabbix server báo lỗi ko select được. do kiểu dữ liệu trả về k khớp. ví dụ bảng alert trường message kiểu dữ liệu là nvarchar, nhưng select zabbix server báo lỗi 😐 phải drop cả bảng đi để sửa lại cái trường đó sang varchar.
– perfomance Chậm hơn mysql rất nhiều. Mở web lên vào zabbix, bấm sang mục host phải 5s mới có kết quả, show debug lên thấy mỗi click chuột, zabbix chạy có lúc lên tới 6k câu SQL vào database. con số này còn tăng lên nữa theo số lượng host mới đc add vào.
==> mệt mỏi quá, anh em quyết quay về zabbix native, lựa chọn ở đây mà mysql hay postgres, cả 2 thằng đều đc zabbix hỗ trợ native. Tuy nhiên do đã chịu đựng quá đủ với mysql nên đổi qua postgres.
Môi trường: Ubuntu 20
DB: postgres 12
Quá trình cài đặt thì thực hiện theo trang chủ zabbix, tới phần import DB vào postgres thì đánh partition cho trường clock của bảng:
'TRENDS', 'TRENDS_UINT', 'HISTORY', 'HISTORY_LOG', 'HISTORY_STR', 'HISTORY_TEXT', 'HISTORY_UINT','ALERTS'
Đây là script cấu trúc bảng history, các bảng khác tươg tự
-- Table: public.history
-- DROP TABLE public.history;
CREATE TABLE IF NOT EXISTS public.history
(
itemid bigint NOT NULL,
clock integer NOT NULL DEFAULT 0,
value double precision NOT NULL DEFAULT '0'::double precision,
ns integer NOT NULL DEFAULT 0
) PARTITION BY RANGE (clock);
ALTER TABLE public.history
OWNER to zabbix;
-- Index: history_1
-- DROP INDEX public.history_1;
CREATE INDEX history_1
ON public.history USING btree
(itemid ASC NULLS LAST, clock ASC NULLS LAST)
;
-- Partitions SQL
CREATE TABLE IF NOT EXISTS public.history_p_2021_06_01 PARTITION OF public.history
FOR VALUES FROM (0) TO (1622566800);
ALTER TABLE public.history_p_2021_06_01
OWNER to zabbix;
CREATE TABLE IF NOT EXISTS public.history_p_2021_06_01 PARTITION OF public.history
FOR VALUES FROM (0) TO (1622566800);
...
ALTER TABLE public.history_p_p_2021_07_31
OWNER to zabbix;
Như các bạn thấy, mỗi ngày 1 partition theo range của clock. (clock là epoch time)
Tiếp theo, tunning các con số cấu hình cho postgres, các bạn có thể lên trang này để generate các con số config theo điều kiện của mình:
https://pgtune.leopard.in.ua/#/
Sau khi đánh partition xong, cho zabbix đẩy data vào, select thử history theo clock
explain (format json) select from history where clock >= 1623762000 and clock <= 1623804210
Wtf, câu select trên vẫn fullscan table, nó đi tìm data lần lượt trên tất cả partition hiện có rồi mới trả về 😐
Qua tìm hiểu thì hoá ra thiếu config trong /etc/postgresql/12/main/postgresql.conf
constraint_exclusion = partition # on, off, or partition
Lọ mọ cấu hình vào restart, select thử lại theo câu lệnh trên xem nó scan những partition nào
explain (format json) select from history where clock >= 1623762000 and clock <= 1623804210
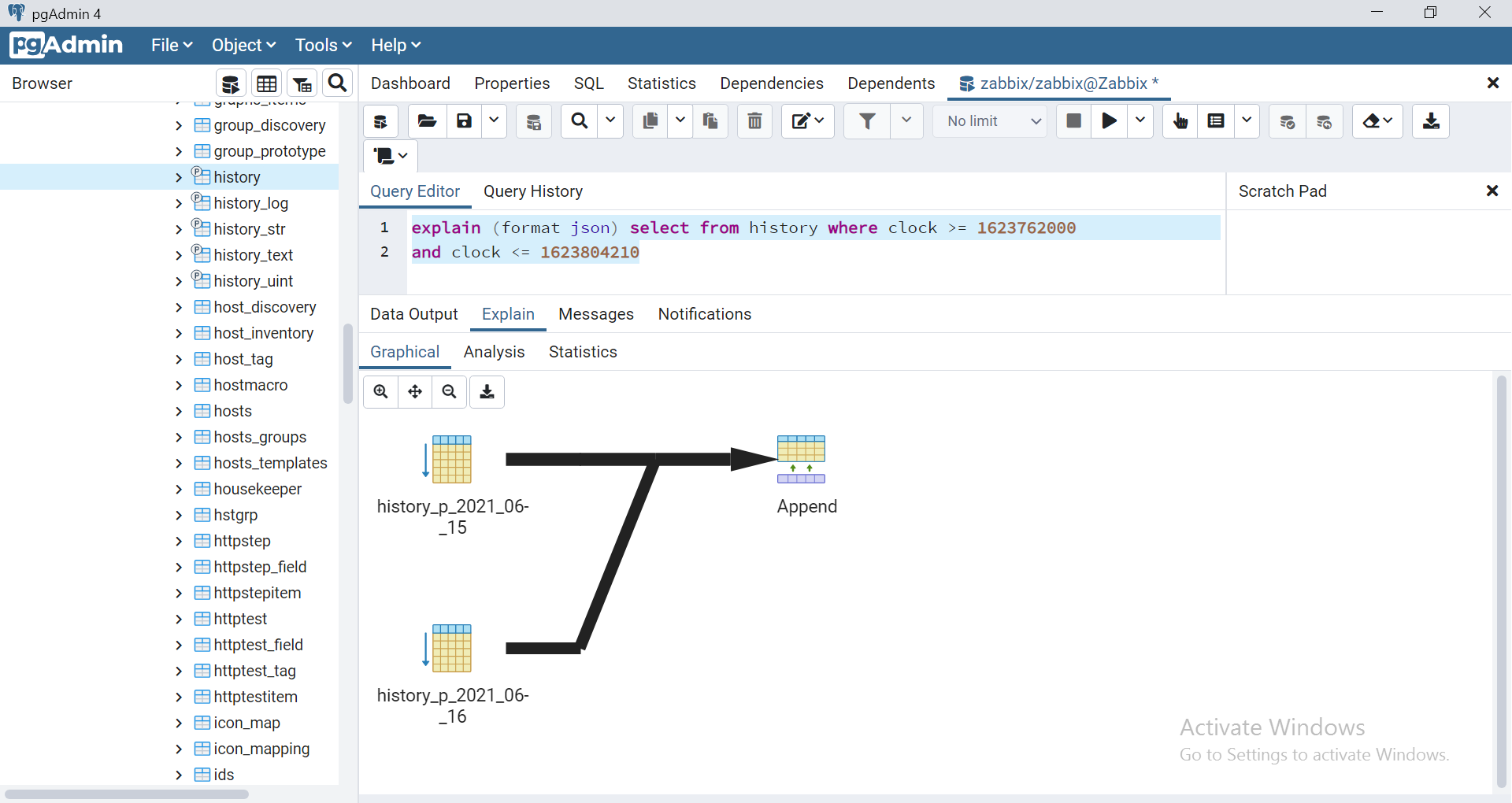
Như vậy là đã OK, chỉ scan trong 2 partition liên quan theo range của clock.
Tạm thời yên tâm về mặt truy vấn.
tiếp theo là đánh partition tự động, do nếu insert vào 1 row có clock nằm ngoài range của partition thì sẽ bị lỗi, do DB ko biết phải cho nó vào đâu. Viết 1 script bằng python đánh tự động partition cho các bảng này. Nguyên tắc tháng T thì đánh partition cho T+1
Script, các bạn thay IP, user, password vào để sử dụng. viết bằng python3, cần cài thêm psycopg2 để kết nối postgres yum install -y python3-psycopg2.x86_64
Cho chạy cái này vào đầu tháng
import datetime
import time
from calendar import monthrange
import psycopg2
import logging
logging.basicConfig(
format='%(asctime)s %(levelname)-8s %(message)s',
level=logging.INFO,
datefmt='%Y-%m-%d %H:%M:%S')
# dsnStr="(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.16.28.70)(PORT=1521))(CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=PDBZBX)))"
# useridOra = 'ZABBIX'
# passwdOra = 'ZBXfintech2021'
# logging.info('Khoi tao ket noi toi database: {}'.format(dsnStr))
conn = psycopg2.connect(
host="postgres-IP",
database="zabbix",
user="zabbix",
password="password")
curs = conn.cursor()
logging.info('Khoi tao ket noi toi database thanh cong')
LISTABLES = ['TRENDS', 'TRENDS_UINT', 'HISTORY', 'HISTORY_LOG', 'HISTORY_STR', 'HISTORY_TEXT', 'HISTORY_UINT','ALERTS']
def gen_sql(table):
logging.info('generate sql cho table: {}'.format(table))
dateformat = 'P_%Y_%m_%d'
TODAY = datetime.date.today()
THIS_MONTH = TODAY.month
NEXT_MONTH = THIS_MONTH+1 if THIS_MONTH < 12 else 1
BASEDAY = datetime.date.today().replace(month=NEXT_MONTH)
DAYS_OF_MONTH = monthrange(BASEDAY.year,BASEDAY.month)[1]
# sql = """ALTER TABLE {} MODIFY
# PARTITION BY RANGE (CLOCK) (""".format(table)
bodysql = []
for i in range(0,DAYS_OF_MONTH,1):
basedate = datetime.date(year=BASEDAY.year,month=BASEDAY.month,day=1+i)
basedate_for_epoch = basedate + datetime.timedelta(1)
partitionname = datetime.datetime.strftime(basedate,dateformat)
epoch_date = datetime.datetime.strftime(basedate_for_epoch,dateformat)
epochtime = int(time.mktime(time.strptime(epoch_date, dateformat)))
epoch_date_from = datetime.datetime.strftime(basedate,dateformat)
epochtime_from = int(time.mktime(time.strptime(epoch_date_from, dateformat)))
# bodysql.append("PARTITION {} VALUES LESS THAN ({})".format(partitionname,epochtime))
# sql = "ALTER TABLE {} ADD PARTITION {} VALUES LESS THAN ({})".format(table,partitionname,epochtime)
sql = "CREATE TABLE public.{0}_P_{1} PARTITION OF public.{0} FOR VALUES FROM ({3}) TO ({2})".format(table,partitionname,epochtime,epochtime_from)
logging.info(sql)
curs.execute(sql)
conn.commit()
logging.info('SQL executed')
# sql+=",".join(bodysql)
# sql+=""") ONLINE"""
# logging.info('SQL : {}'.format(sql))
# return sql
for table in LISTABLES:
gen_sql(table)
# sql_string = gen_sql(table)
# logging.info('execute sql on {}'.format(table))
# logging.info('executed')