I- Chuẩn bị
3 máy centos 7: <hostname>:<IP>
– node-master: 192.168.151.171
– node1: 192.168.151.172
– node2: 192.168.151.173
Phần môi trường cần cài đặt trên 3 máy:
java jdk 1.8 trở lên
yum install -y epel-release vim curl wget telnet
disable firewall hoặc mở sẵn port
service iptables stop
chkconfig iptables off
II- Kiến trúc hadoop cluster
Kiến trúc hadoop cluster gồm 2 loại node chính:
o Master node: lưu giữ thông tin về hệ thống file phân tán, tương đương với bảng inode của ext3, ngoài ra còn có nhiệm vụ lên kế hoạch phân bổ tài nguyên. Trong guide này, node master có 2 nhiệm vụ chính:
o Name node: quản lý hệ thống file phân tán, nắm thông tin block dữ liệu nào nằm ở đâu trong cluster.
o ResourceManager: quản lý các job của YARN và quản lý các job được xếp lịch chạy trên các node slave.
o Slave node: lưu dữ liệu thực và cung cấp sức mạnh phần cứng để chạy các job, trong lab này là node1 và node2:
o Datanode quản lý các block dữ liệu về mặt vật lý.
o Nodemanager, quản lý thực hiện các task trên node.
III- Cấu hình hệ thống.
1. Tạo file host trên mỗi node
192.168.150.171 node-master
192.168.150.172 node1
192.168.150.173 node2
2. Tạo keypair xác thực cho hadoop user
Master node sẽ sử dụng ssh để kết nối tới các node khác và quản lý cluster. Thực hiện:
Log in vào node-master với user hadoop , tạo 1 ssh-key gán cho user hadoop. Sau đó thử ssh bằng user hadoop vào từng node 1, nếu k hỏi password tức là thành công
ssh hadoop@node-master
ssh-keygen -b 4096
ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node-master
ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node1
ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node2
3. Download và giải nén bộ cài hadoop
Đăng nhập vào node-master với user hadoop, download bộ cài hadoop từ trang chủ
cd
wget http://mirrors.viethosting.com/apache/hadoop/common/hadoop-2.8.4/hadoop-2.8.4.tar.gz
tar zxvf hadoop-2.8.4.tar.gz
mv hadoop-2.8.4 hadoop
4. Thiết lập biến môi trường.
Thêm folder hadoop vừa giải nén vào biến môi trường PATH
vim /home/hadoop/.bash_profile
Thêm dòng sau:
PATH=/home/hadoop/hadoop/bin:/home/hadoop/hadoop/sbin:$PATH
IV- Cấu hình Master Node
1. Thiết lập JAVA_HOME
Tìm vị trí cài đặt java, mặc định ở /usr/java/jdk1.8.0_171-amd64
Có thể tìm bằng cách:
update-alternatives --display java
Thêm các dòng sau vào /home/hadoop/.bash_profile
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
Đường dẫn JAVA_HOME thay đổi tuỳ từng lúc nhé. ở đây mình làm ra thế.
2. Đặt đường dẫn Namenode
Trên mỗi node đều cần thiết đặt file core-site.xml, ở đây ở địa chỉ:
~/hadoop/etc/hadoop/core-site.xml
Trong đó ~/hadoop/etc/hadoop/ là thư mục chứa file cấu hình của hệ thống hdfs, nhớ đường dẫn này, sẽ sử dụng ở các bước sau:
Nội dung file:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node-master:9000</value>
</property>
</configuration>
Chỉnh sửa file hdfs-site.conf
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dataNode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Lưu ý thuộc tính dfs.replication, thuộc tính này là số lần dữ liệu được nhân bản (nhằm mục đích dự phòng, node này chết thì còn bản sao ở node khác). ở đây mình có 2 node có thể set mục này tối đa bằng 2 để dữ liệu được nhân bản trên cả 2 node (tốn tài nguyên). Không được đặt con số này nhiều hơn số datanode mà chúng ta có.
3. Thiết lập Yarn làm Job Scheduler
Đổi tên file mapred-site.xml.template thành mapred-site.xml. Nội dung:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Lưu ý giá trị là yarn, tốt nhất tìm vị trí khoá như trên rồi sửa lại.
Sửa file yarn-site.xml
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4. Cấu hình Slave
Khai báo danh sách các datanode mà ta có với namenode, sửa file ~/hadoop/etc/hadoop/slaves
Điền mỗi namenode 1 dòng
node1
node2
5. Cấu hình phân bổ RAM
Việc phân bổ ram có thể làm để những node có ram yếu có thể chạy được. các giá trị mặc định được thiết kế cho các máy 8GB ram trở lên. Dưới đây là những tuỳ chỉnh cho những node 2GB Ram.
6. Các thuộc tính phân bổ RAM
Một Yarn job được chạy với 2 loại:
– Một application manager: chịu trách nhiệm giám sát ứng dụng và phối hợp để phân phối excecutor trong cluster (phân phối xem node nào sẽ thực hiện job).
– Một số executor được tạo bởi application manager chạy các job. Đối với các mapredure job, chúng thực hiện các tiến trình map và redure song song.
Cả 2 app trên chạy trên slave node. Mỗi slave node chạy một NodeManager dạng deamon, chịu trách nhiệm đối với việc tạo container trên mỗi node. Toàn bộ cluster chịu sự quản lý của ResourceManager, lên kế hoạch phân bổ các container trên toàn bộ slavenode, dựa trên nhu cầu cần thiết cho mỗi action hiện tại.
Bốn hình thức cấp phát tài nguyên được cấu hình chuẩn để cluster có thể làm việc:
– Số bộ nhớ RAM có thể cung cấp cho Yarn container trên mỗi node. Giới hạn này nên để cao, nếu không việc cung cấp tài nguyên cho container sẽ bị reject, ứng dụng sẽ fail. Tuy nhiên, không được cấp toàn bộ số RAM trên node. Giá trị này được cấu hình trên file yarn-site.xml với key = yarn.nodemanager.resource.memory-mb
– Lượng bộ nhớ mà 1 node đơn có thể chiếm và số bộ nhớ cấp phát nhỏ nhất được cho phép. Được cấu hình tại yarn-site.xml với key = yarn.scheduler.minimum-allocation-mb
– Lượng RAM được cấp cho mỗi tiến trình map hoặc redure. Nên nhỏ hơn số bộ nhớ tối đa. Được cấu hình tại file mapred-site.xml với key = mapreduce.map.memory.mb và mapreduce.reduce.memory.mb
– Lượng RAM sẽ được cấp cho ApplicationMaster.
Hình minh hoạ cho các cấu hình này:

Ví dụ về cấu hình cho node 2GB RAM
Property Value
yarn.nodemanager.resource.memory-mb 1536
yarn.scheduler.maximum-allocation-mb 1536
yarn.scheduler.minimum-allocation-mb 128
yarn.app.mapreduce.am.resource.mb 512
mapreduce.map.memory.mb 256
mapreduce.reduce.memory.mb 256
Sửa file /home/hadoop/hadoop/etc/hadoop/yarn-site.xml và thêm các dòng sau:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
Sửa file /home/hadoop/hadoop/etc/hadoop/mapred-site.xml và thêm các dòng sau:
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>256</value>
</property>
V- Nhân bản cấu hình vừa thiết lập tới các slave node
1- Copy hadoop sang slave node:
cd /home/hadoop/
scp hadoop-*.tar.gz node1:/home/hadoop
scp hadoop-*.tar.gz node2:/home/hadoop
Kết nối tới node1, node2 qua SSH, giải nén 2 gói vừa copy sang
tar -xzf hadoop-2.8.1.tar.gz
mv hadoop-2.8.1 hadoop
exit
Quay lại node-master, copy config sang
for node in node1 node2; do
scp ~/hadoop/etc/hadoop/* $node:/home/hadoop/hadoop/etc/hadoop/;
done
2- Format HDFS
HDFS sau khi tạo cũng cần phải được format trước khi sử dụng, tương tự như đối với bất kỳ file system truyền thống nào khác.
Trên node master chúng ta gõ lệnh
hdfs namenode -format
Đến đây thì việc cài đặt HDFS đã hoàn tất và sẵn sàng để chạy
VI- Chạy và monitỏ HDFS
1- Start và Stop HDFS
Mọi thao tác được thực hiện trên node-master
start-dfs.sh
stop-dfs.sh
Sau khi chạy lệnh start, master sẽ tự động SSH sang node1+node2 (qua key đã tạo ở trên) để tiến hành bật datanode. Kiểm tra các tiến trình đã được khởi động trên mỗi node bằng lệnh jps , kết quả như bên dưới, bao gồm PID và process name
21922 Jps
21603 NameNode
21787 SecondaryNameNode
19728 DataNode
19819 Jps
2- Monitor HDFS cluster.
Lấy thông tin về cluster đang chạy bằng lệnh:
hdfs dfsadmin -report
Lấy các thông tin về các lệnh được hỗ trợ bằng lệnh help
hdfs dfsadmin -help
Ngoài ra còn có thể truy cập trang web quản trị:
http://node-master-IP:50070
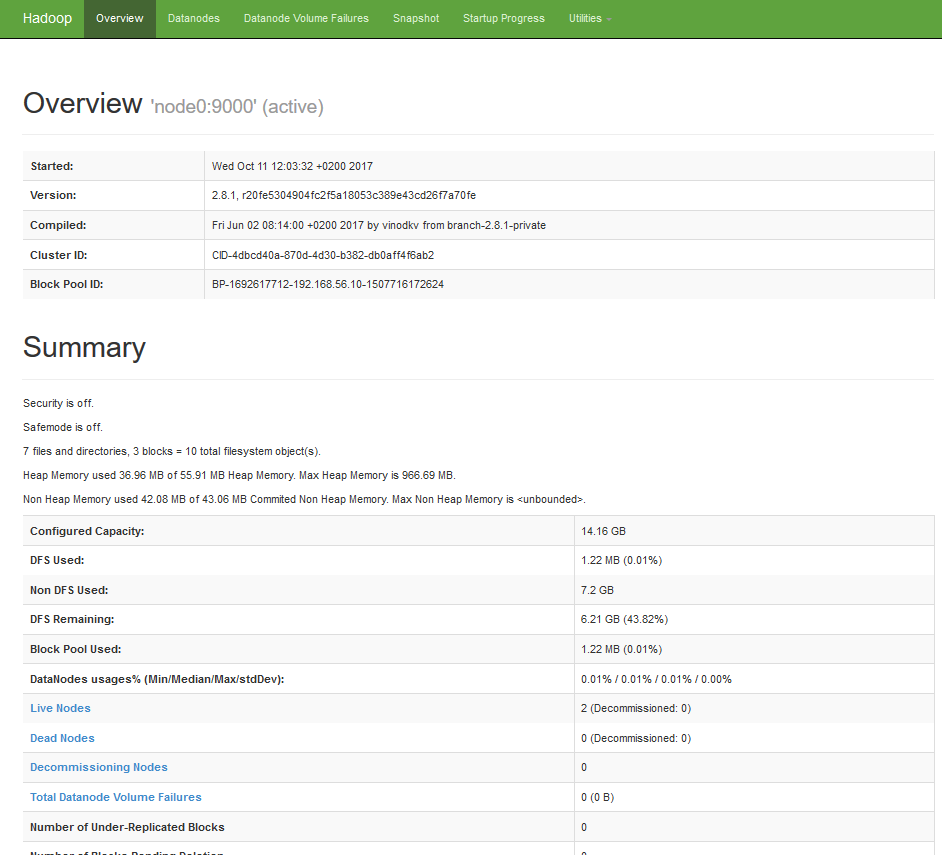
3- Test đẩy dữ liệu lên HDFS
Sử dụng lệnh hdfs dfs để thao tác với dữ liệu trên hdfs. Đầu tiên, ta tạo một thư mục mặc định, tất cả các lệnh khác sẽ sử dụng đường dẫn quan hệ tới thư mục home mặc định này.
hdfs dfs -mkdir -p /user/hadoop
Tạo thêm thư mục books bên trong hdfs
hdfs dfs -mkdir books